SALSA (Smart Application for Large Scale Analysis) est la plateforme de gestion des données et des analyses à grande échelle développée par le DEVC et désormais utilisée par plusieurs partenaires du CEESAR.

Projet terminé ✓
Contexte
Le développement et la mise au point d’objets connectés nécessite l’analyse des larges quantités de données qu’ils peuvent produire grâce à l’ensemble des capteurs dont ils sont équipés. C’est notamment le cas des véhicules connectés et automatisés, dont le fonctionnement repose sur la perception et l’interprétation de l’environnement par un nombre important de capteurs (LIDAR, RADAR, Caméras) délivrant des données particulièrement riches, dont l’utilisation mal gérée dans des situations à risque peut conduire à des drames.
L’identification et la caractérisation de ces situations problématiques nécessite la fouille de ces données, fouille qui repose sur le développement de « features » caractérisant les situations, leur annotation et leur classification dans une base de données structurée.
Les défis du processus de traitement
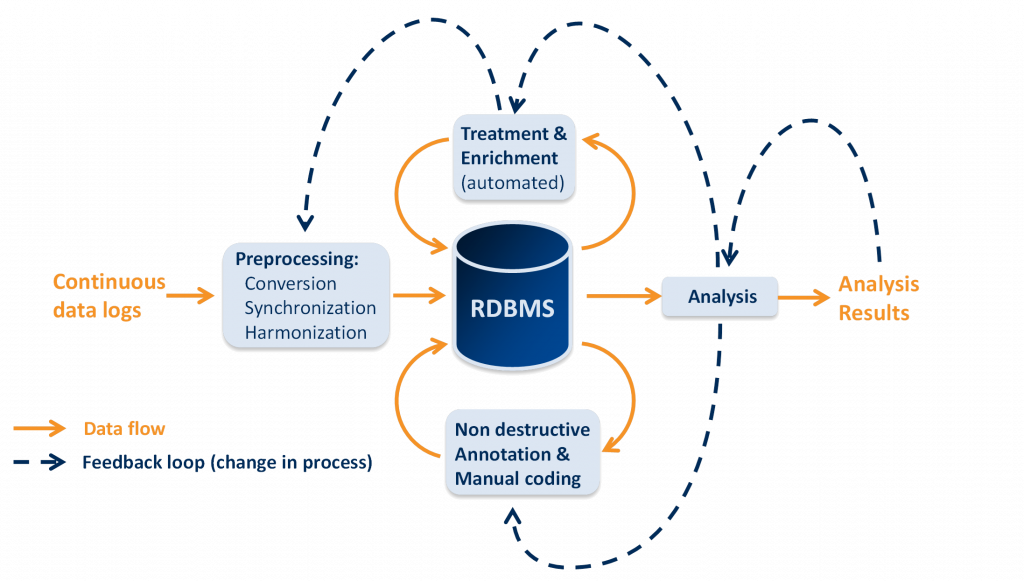
La construction de cette base de données structurée présente de nombreux défis:
- Le processus est continu : des résultats doivent être exploitables alors même que des données continuent d’être importées.
- Le processus est non-linéaire : des données, potentiellement dépendantes les unes des autres, sont importées, enrichies, annotées et exportées simultanément.
- Le jeu de données est enregistré dans des situations non contrôlées : un traitement défini pour des conditions « idéales » peut ne pas être robuste dans d’autres cas.
- Les données sont utilisées de manière collaborative : des analystes, des développeurs, des annotateurs doivent pouvoir travailler en même temps sur le même jeu de données.
- Le processus est itératif : les premières analyses apporteront des changements à la définition des traitements.
Différentes approches classiques d’exploitation des données sont généralement observées :
- L’emploi d’outils « métier », implémentant des fonctions conviviales (visualisation…), mais communiquant mal entre eux, et gérant mal les grands jeux de données ou les processus complexes.
- Le développement d’un outil dédié, où des fonctions même « basiques » peuvent nécessiter un important effort d’implémentation, et dont les évolutions deviendront de plus en plus couteuses au fur et à mesure que les besoins évoluent.
Ces deux approches présentent rapidement leurs limites dans les projets complexes (UDRIVE, MOOVE…), généralement lieux de difficultés à communiquer entre 2 catégories d’utilisateurs des données :
- les experts métier comprennent intimement les données d’entrée, leur sens physique, mais sont généralement désemparés par l’échelle des traitements.
- les data-scientists maitrisent les outils du big-data, mais n’ont que rarement les connaissances métier et les outils leur permettant d’interpréter les relations qu’ils mettent en évidence.
SALSA réalise le chainon manquant entre ces deux mondes : c’est à la fois une application intégrée proposant de nombreuses fonctionnalités de traitement, de visualisation, d’annotation des données, et un framework ouvert et générique, permettant l’adaptation à de nombreux besoins différents les uns des autres.
Les exigences de conception de SALSA
Les exigences qui ont guidé sa conception sont:
- Robustesse: les erreurs humaines ou de programmation ne doivent pas aboutir à la destruction de données, ou bloquer le fonctionnement du système.
- Efficacité: quand un algorithme est changé ou une information codée manuellement, seules les données dépendantes des modifications sont recalculées, ce qui évite de réévaluer inutilement des algorithmes dont les résultats sont toujours à jour.
- Concurrence: les développeurs et annotateurs peuvent travailler simultanément, en même temps que des données sont importées, en même temps que d’autres sont mises à jour, en même temps que d’autres encore sont extraites pour analyse…
- Consistance: chaque action, création de nouvelle variable, ajout d’algorithme etc… est tracée. Les traitements sont appliqués de manière homogène à l’ensemble des données et il est possible de reproduire pour chacune la chaîne de traitement qui l’a créé : SALSA permet de créer un ensemble de données auto-documenté.
- Interactivité: l’utilisateur peut voir immédiatement l’impact de ses changements dans les algorithmes ou les annotations. Les données affichées dans SALSA sont systématiquement à jour (mise à jour à la volée si l’utilisateur demande l’affichage de données persistantes non-encore calculées ou rafraichies dans la base).
- Scalabilité: les traitements définis sont exécutés à grande échelle, en parallèle, sur différents enregistrements.
- Maintenance réduite: il n’est pas nécessaire de maintenir manuellement la structure de la base de données et le catalogue correspondant. Il n’est pas nécessaire non plus de créer et maintenir un script principal exécutant dans le bon ordre l’ensemble des algorithmes, et réalisant le lien entre ceux-ci et les données.
- Disponibilité : seules les mises à jour de la structure de la base rendent l’outil indisponible, une étape automatisée, qui ne prend que quelques minutes.
- Généricité : l’outil n’implémente aucune spécificité « métier », et repose sur des concepts génériques et sur un nombre restreint de règles. Une fois ces concepts maitrisés, l’utilisateur les combine de manière créative pour répondre à des besoins divers. Les tâches techniques (gestion de données, gestion des traitements) sont gérées par l’outil, et séparées des tâches scientifiques (définition de données, d’algorithmes) de l’utilisateur. Les scripts utilisateurs ne sont donc pas « pollués » de routines d’accès aux données et sont donc plus lisibles, plus faciles à maintenir, réutilisables pour de nouveaux projets, et avec d’autres outils.
Principes de fonctionnement
SALSA atteint ces objectifs grâce à un modèle déclaratif : l’utilisateur définit son jeu de données en déclarant une source de données, des conteneurs pour les données dérivées, des scripts implémentant ses algorithmes métier, des entités à annoter, l’interface d’annotation correspondante etc…
Lorsque l’utilisateur utilise l’outil de manière interactive ou lors des traitements par lot, ces déclarations sont combinées et transformées par SALSA en ordres (modèle impératif) pour la gestion de la base de données et des traitements.
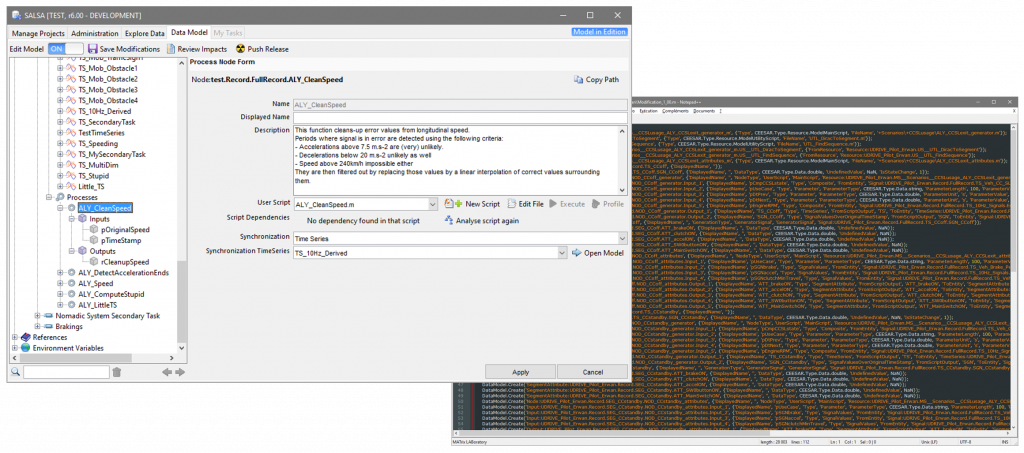
Le comportement de l’outil est ainsi basé sur un modèle de données, défini par l’utilisateur via l’interface graphique et/ou l’API dédiée.
Ce modèle est à la fois un modèle relationnel ou hiérarchique (des conteneurs de données contiennent eux même d’autres conteneurs de données) et un graphe de dépendance (les liens créés par les scripts utilisateurs peuvent balayer plusieurs niveaux hiérarchiques).
Le modèle de données est défini par l’utilisateur, soit dans une interface graphique, soit en utilisant une API, ce qui permet d’automatiser la création de chaines de traitement.
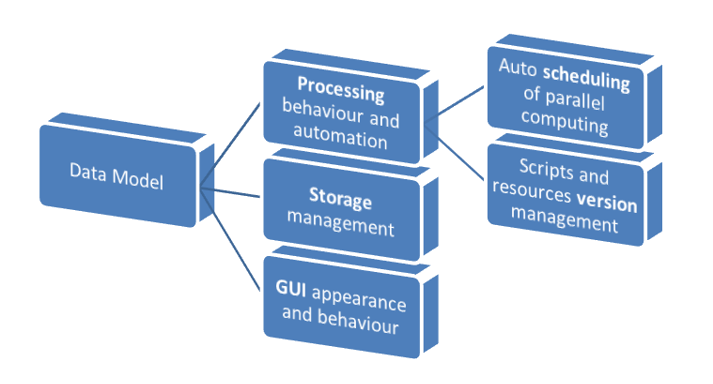
SALSA utilise l’ensemble des liens créés dans le modèle, de manière explicite ou implicite par l’utilisateur, pour gérer automatiquement le stockage et les traitements, et l’ensemble de l’interface utilisateur (affichage, annotation etc..)
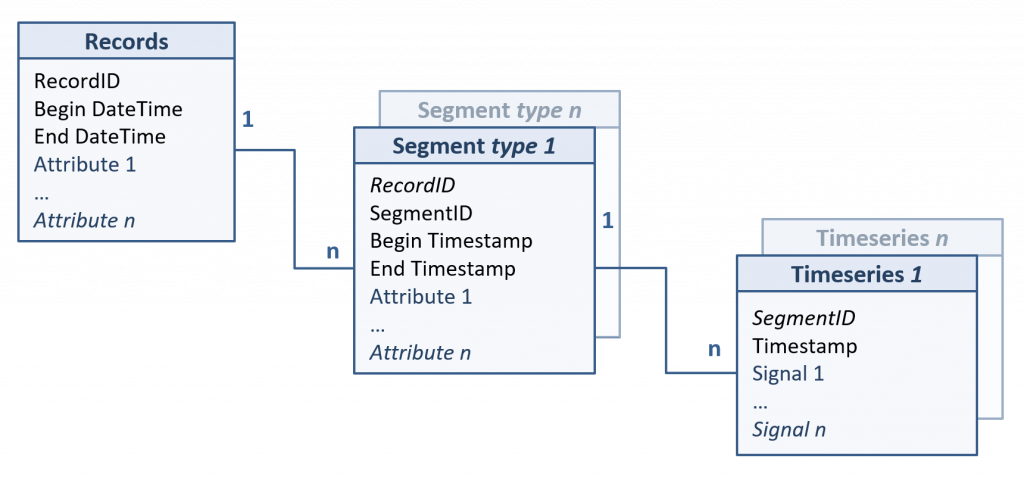
Les éléments principaux définis dans ce modèle sont les suivants :
- Enregistrements : par exemple, un roulage
- Segments : sous-ensembles temporels d’un enregistrement
- Séries temporelles : signaux acquis ou dérivés
- Attributs caractérisant/résumant un enregistrement ou un segment
- Références permettant d’associer des métadonnées, utilisables dans les algorithmes, aux différentes modalités des signaux et des attributs.
- Processes reliant les données et les algorithmes définis dans les scripts utilisateurs
SALSA peut manipuler tous les types de données habituels (nombres à virgule flottant, entiers, chaines de caractères), mais aussi des variables catégorielles et des variables vectorielles : signaux et attributs non-scalaires (e.g. signaux à 3 dimensions, distributions stockées dans des attributs…)
SALSA se présente sous la forme d’une « toolbox » MATLAB aisément déployable et largement documentée. Le langage MATLAB peut donc être utilisé pour le développement d’algorithmes métier, accompagné ou non de modules développés dans tous les autres langages s’interfaçant avec MATLAB : Python, C, C++, java, C#, Perl…
SALSA est un développement interne du CEESAR, permettant l’exploitation de l’ensemble des jeux de données collectés par l’équipe DEVC, lors de différents projets (EUROFOT, UDRIVE, SCOOP@F…). Cumulées, ces bases représentent plus de trois millions de kilomètres de données continues et particulièrement riches (CAN, capteurs additionnels, vidéo…).
SALSA est également utilisé par l’ensemble du consortium UDRIVE, par l’Université Gustave Eiffel, par VEDECOM et ses partenaires dans le cadre du projet MOOVE (~1 000 000 km collectés), et supporte l’extraction de scénarios issues de données de roulage dans le cadre d’ADSCENE, initiative des constructeurs automobiles français visant à la constitution d’une base de données de scénarios dédiée à la validation des véhicules à délégation de conduite.